基于知识蒸馏的BERT模型压缩
- 2021-12-09 13:55:44
- 科技圈

大数据文摘授权转载自数据派编译:孙思琦、成宇、甘哲、刘晶晶
在过去一年里,语言模型的研究有了许多突破性的进展, 比如GPT用来生成的句子足够以假乱真[1];BERT, XLNet, RoBERTa [2,3,4]等等作为特征提取器更是横扫各大NLP榜单。但是,这些模型的参数量也相当惊人,比如BERT-base有一亿零九百万参数,BERT-large的参数量则高达三亿三千万,从而导致模型的运行速度过慢。为了提高模型的运行时间,本文率先提出了一种新的知识蒸馏 (Knowledge Distillation) [5] 方法来对模型进行压缩,从而在不损失太多精度的情况下,节省运行时间和内存。文章发表在EMNLP 2019。
“耐心的知识蒸馏”模型
具体来说,对于句子分类类型的任务,当普通的知识蒸馏模型用来对模型进行压缩的时候, 通常都会损失很多精度。原因是学生模型 (student model) 在学习的时候只是学到了教师模型 (teacher model) 最终预测的概率分布,而完全忽略了中间隐藏层的表示。
就像老师在教学生的时候,学生只记住了最终的答案,但是对于中间的过程确完全没有学习。这样在遇到新问题的时候,学生模型犯错误的概率更高。基于这个假设,文章提出了一种损失函数,使得学生模型的隐藏层表示接近教师模型的隐藏层表示,从而让学生模型的泛化能力更强。文章称这种模型为“耐心的知识蒸馏”模型 (Patient Knowledge Distillation, 或者PKD)。
因为对于句子分类问题,模型的预测都是基于[CLS]字符的特征表示之上,比如在这个特征上加两层全连接。因此研究者提出一个新的损失函数,使得模型能够同时学到[CLS]字符的特征表示:
其中M是学生的层数(比如3,6), N是老师模型的层数(比如12,24),h是[CLS]在模型中隐藏层的表示,而i, j则表示学生-老师隐藏层的对应关系,具体如下图所示。比如,对于6层的学生模型,在学习12层的教师模型的时候, 学生模型可以学习教师模型的 (2,4,6,8,10)层隐藏层的表示 (左侧PKD-skip), 或者教师模型最后几层的表示 (7,8,9,10,11, 右侧PKD-last). 最后一层因为直接学习了教师模型的预测概率,因此略过了最后一个隐藏层的学习。
验证猜测
研究者将提出的模型与模型微调(fine-tuning)和正常的知识蒸馏在7个句子分类的保准数据集上进行比较,在12层教师模型蒸馏到6层或者3层学生模型的时候,绝大部分情况下PKD的表现都优于两种基线模型。并且在五个数据集上SST-2 (相比于教师模型-2.3%准确率), QQP (-0.1%), MNLI-m (-2.2%), MNLI-mm (-1.8%), and QNLI (-1.4%) 的表现接近于教师模型。具体结果参见图表1。从而进一步验证了研究者的猜测,学习了隐藏层表示的学生模型会优于只学教师预测概率的学生模型。
图表1
在速度方面,6层transformer模型几乎可以将推理 (inference) 速度提高两倍,总参数量减少1.64倍;而三层transformer模型可以提速3.73倍,总参数两减少2.4倍。具体结果见图表2。
图表2
Radford, Alec, et al. "Language models are unsupervised multitask learners." OpenAI Blog 1.8 (2019).
Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
Yang, Zhilin, et al. "XLNet: Generalized Autoregressive Pretraining for Language Understanding." arXiv preprint arXiv:1906.08237 (2019).
Liu, Yinhan, et al. "Roberta: A robustly optimized BERT pretraining approach." arXiv preprint arXiv:1907.11692 (2019).
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
Siqi Sun: is a Research SDE in Microsoft. He is currently working on commonsense reasoning and knowledge graph related projects. Prior joining Microsoft, he was a PhD student in computer science at TTI Chicago, and before that he was an undergraduate student from school of mathematics at Fudan University.
Yu Cheng: is a senior researcher at Microsoft. His research is about deep learning in general, with specific interests in model compression, deep generative model and adversarial learning. He is also interested in solving real-world problems in computer vision and natural language processing. Yu received his Ph.D.from Northwestern University in 2015 and his bachelor from Tsinghua University in 2010. Before join Microsoft, he spent three years as a Research Staff Member at IBM Research/MIT-IBM Watson AI Lab.
Zhe Gan: is a senior researcher at Microsoft, primarily working on generative models, visual QA/dialog, machine reading comprehension (MRC), and natural language generation (NLG). He also has broad interests on various machine learning and NLP topics. Zhe received his PhD degree from Duke University in Spring 2018. Before that, he received his Master"s and Bachelor"s degree from Peking University in 2013 and 2010, respectively.
Jingjing (JJ) Liu: is a Principal Research Manager at Microsoft, leading a research team in NLP and Computer Vision. Her current research interests include Machine Reading Comprehension, Commonsense Reasoning, Visual QA/Dialog and Text-to-Image Generation. She received her PhD degree in Computer Science from MIT EECS in 2011. She also holds an MBA degree from Judge Business School at University of Cambridge.Before joining MSR, Dr.Liu was the Director of Product at Mobvoi Inc and Research Scientist at MIT CSAIL.
代码已经开源在:
https://github.com/intersun/PKD-for-BERT-Model-Compression
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京・清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn
本文首发于微信公众号:大数据文摘。文章内容属作者个人观点,不代表和讯网立场。投资者据此操作,风险请自担。


- 奇瑞四大品牌集结北京车展 以世界级水准引领汽车产业新浪潮2024-04-26
- 油电协同多线并举 奇瑞品牌携7款重磅车型亮相北京车展2024-04-26
- 这才是远离春季过敏的终极大招――约克VRF中央空调2024-04-25
- 中国力量!山石网科再次入选Gartner《NDR市场指南》2024-04-25
- 影像佳作 有融乃大 佳能携丰富的专业影像设备及多样化专业影像解决方案亮相CCBN20242024-04-25

- 2
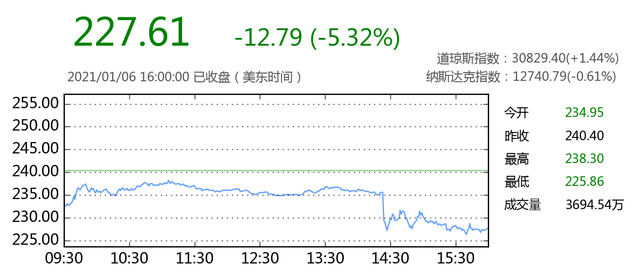 阿里巴巴美股直线跳水跌近5% 是怎么回事?
阿里巴巴美股直线跳水跌近5% 是怎么回事?
2021-12-09
- 2
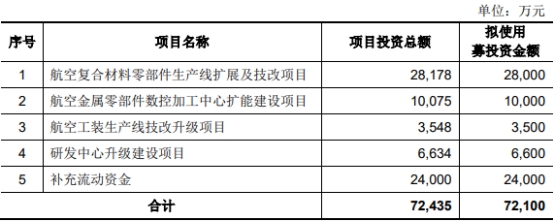
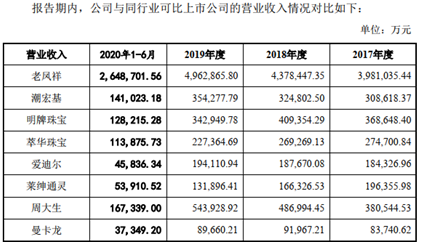 曼卡龙成功过会 “区域深耕”折射实力不济
曼卡龙成功过会 “区域深耕”折射实力不济
2021-12-09
- 2
 券商板块:之前跌得有多惨 现在反弹力度就有多强
券商板块:之前跌得有多惨 现在反弹力度就有多强
2021-12-09
- 2
 福特北美追加召回27万辆搭载2.5升引擎溜车隐患Fusion
福特北美追加召回27万辆搭载2.5升引擎溜车隐患Fusion
2021-12-09
热门阅读
- 1【算力先锋】并行科技董事长陈健:大模型必选超算架构算力,算力调度在于用户需求
- 2iCAR 全新车型全球首秀,V23、X25首次参与互动,升维iCAR即将热力席卷北京车展
- 3当下AI驱动下的广告营销,是一个“领先的落后行业” | 第八届社交媒体风向大会
- 4佳能EOS青年影像学院暨第二届佳能大学生影像节在广州盛大启幕
- 5蓄势突破,全面跃升,新东方智慧教育亮相第83届全国教育装备展
- 6奇瑞风云全面覆盖混动/增程/纯电市场 两年内发布11款新能源车型
- 7"让人人享有精致科技的乐趣”,看升维iCAR如何引爆行业"对撞”
- 8赫特擦窗机器人广交会首秀,开启AI变频擦窗新时代
- 9连续五年上榜胡润全球独角兽榜 e签宝依托AI+电子签名能力荣膺
- 10BOE(京东方)2024年一季度净利润预计8亿元-10亿元,三位数增长叩响高质量发展"开门红”